
Wohin gehen unsere Daten eigentlich? KI und Vertraulichkeit verständlich erklärt
Es ist die Frage, die in fast jedem Erstgespräch fällt, oft schon in den ersten zehn Minuten: „Und wo landen dann unsere Daten?“ Die Sorge dahinter ist berechtigt. Wer eine Kundenanfrage, eine Kalkulation oder einen Vertragsentwurf in ein KI-Werkzeug eingibt, vertraut diesem Werkzeug etwas an.
Vorweg, damit die Erwartung stimmt: Dieser Artikel ist keine Rechtsberatung. Was Rechtstexte im Einzelfall bedeuten, klären Sie mit Ihrem Datenschutzbeauftragten oder Anwalt. Worum es hier geht, ist etwas anderes: die Themen sichtbar zu machen, an die Sie denken müssen, bevor Sie diese Gespräche führen. Denn wer die richtigen Fragen kennt, bekommt auch von Juristen und Anbietern brauchbare Antworten. Und diese Fragen ergeben sich fast von selbst, sobald man eines verstanden hat: welchen Weg eine Eingabe tatsächlich nimmt.

Danke für das Bild: planet-volumes-unsplash
Der Weg einer Eingabe: was wirklich passiert
Wenn Sie eine Frage in ChatGPT, Claude, Copilot oder ein anderes KI-Werkzeug tippen, passiert technisch Folgendes: Ihre Eingabe wird über das Internet an die Server des Anbieters geschickt. Dort verarbeitet sie das Sprachmodell und schickt die Antwort zurück. Das dauert Sekunden und ist im Prinzip nichts anderes, als eine E-Mail über einen externen Dienstleister zu versenden.
Die entscheidenden Fragen beginnen danach:
Was geschieht mit Ihrer Eingabe, nachdem die Antwort bei Ihnen angekommen ist?
Wird sie gespeichert? Wie lange?
Wer kann sie einsehen?
Wird sie verwendet, um das Modell weiter zu trainieren?
Genau hier liegt der Unterschied zwischen unbedenklicher Nutzung und einem echten Risiko. Und genau hier unterscheiden sich die Angebote am Markt erheblich, oft sogar innerhalb desselben Anbieters.
Speichern ist nicht gleich Trainieren
Zwei Dinge werden in der Diskussion ständig vermischt, dabei sind sie grundverschieden.
Speichern bedeutet: Der Anbieter bewahrt Ihre Eingaben für eine gewisse Zeit auf, etwa damit Sie Ihren Chatverlauf wiederfinden oder damit Missbrauch erkannt werden kann. Das ist bei fast allen Diensten der Fall und für sich genommen kein Drama, solange drei Dinge vertraglich geregelt sind: wer Zugriff hat, wann gelöscht wird, und wo die Daten gespeichert werden. Gerade der Speicherort wird oft übersehen, dabei entscheidet er, welches Recht gilt und welche Behörden im Zweifel Zugriff verlangen können.
Trainieren bedeutet: Ihre Eingaben fließen in die Weiterentwicklung des Modells ein. Das Modell lernt aus dem, was Sie schreiben. Und was ein Modell einmal gelernt hat, lässt sich nicht wieder herauslöschen. Wenn Ihre Preiskalkulation, Ihre Kundenliste oder Ihr Konstruktionsdetail Teil eines Trainingslaufs wird, ist diese Information dauerhaft in der Welt, in welcher Form auch immer.
Die Faustregel, Stand heute: Kostenlose und private Versionen der großen KI-Dienste nutzen Eingaben häufig standardmäßig fürs Training, sofern man dem nicht aktiv widerspricht. Geschäftsversionen, also Business-, Enterprise- und API-Zugänge, schließen das vertraglich aus. Das ist der Kern des Problems mit der sogenannten Schatten-KI: Mitarbeiter, die mangels offizieller Lösung ihren privaten ChatGPT-Account fürs Geschäft nutzen, schicken Firmendaten genau dorthin, wo sie nicht hingehören. Nicht aus böser Absicht, sondern weil niemand ihnen eine Alternative gegeben hat.
Die Vertragsfrage: ohne AV-Vertrag kein Geschäftseinsatz
Sobald personenbezogene Daten im Spiel sind, also Namen, E-Mail-Adressen, Kundendaten, Mitarbeiterinformationen, verlangt die DSGVO einen Auftragsverarbeitungsvertrag mit dem Anbieter. Klingt bürokratisch, ist aber im Kern ein einfaches Versprechen: Der Anbieter verarbeitet Ihre Daten nur in Ihrem Auftrag, nach Ihren Regeln, und steht dafür gerade.
Die großen Anbieter haben hier in den letzten Jahren deutlich nachgebessert. Für die Geschäftsversionen von ChatGPT, Claude, Copilot und Co. gehören solche Verträge inzwischen zum Standard, teils sind sie automatisch Bestandteil der Nutzungsbedingungen, teils müssen sie aktiv abgeschlossen werden. Für private Accounts gibt es sie in der Regel nicht in tragfähiger Form. Auch das ist ein Grund, warum die Privatversion fürs Geschäft tabu sein sollte.
Bleibt die Frage des Serverstandorts. Viele Anbieter verarbeiten Daten in den USA, was derzeit über entsprechende Abkommen rechtlich abgesichert ist. Zunehmend bieten die großen Anbieter aber auch eine Verarbeitung in europäischen Rechenzentren an. Für die meisten Mittelständler ist das eine Komfortfrage, für manche Branchen – etwa im Gesundheitswesen oder bei Berufsgeheimnisträgern – eine harte Anforderung.
Nicht alle Daten sind gleich: das Ampelprinzip
Der häufigste Denkfehler in der Praxis ist ein Alles-oder-nichts-Denken: Entweder KI ist sicher, dann darf alles hinein. Oder sie ist unsicher, dann wird sie verboten. Beides führt in die Irre. Sinnvoller ist es, die eigenen Daten in drei Kategorien zu denken.
Grün: unkritische Daten. Öffentlich verfügbare Informationen, allgemeine Texte, Formulierungshilfen ohne Firmenbezug. Hier ist das Risiko gering, hier kann Ihr Team frei arbeiten und Erfahrung sammeln.
Gelb: interne Daten ohne Personenbezug. Prozessbeschreibungen, technische Dokumentationen, anonymisierte Auswertungen. Diese Daten gehören in ein Werkzeug mit Geschäftsvertrag, Trainingsausschluss und klarer Löschregelung, aber dann spricht wenig gegen die Nutzung.
Rot: sensible Daten. Personenbezogene Daten, Geschäftsgeheimnisse, Kalkulationen, Verträge, alles, was unter besondere Verschwiegenheit fällt. Hier gilt: Entweder das Werkzeug erfüllt nachweislich alle Anforderungen, oder diese Daten bleiben draußen. Oft ist auch Anonymisieren der pragmatische Weg: Die KI braucht selten den echten Kundennamen, um einen guten Antwortentwurf zu schreiben.
Welche Daten bei Ihnen in welche Kategorie fallen, kann Ihnen kein Anbieter abnehmen. Diese Einordnung ist Ihre Hausaufgabe, und sie ist wertvoller als jede Datenschutz-Checkliste aus dem Internet, weil sie zu Ihrem Geschäft passt.
Sonderfall Wissensdatenbank: Die Daten bleiben im Haus. Wirklich alle?
Eine der beliebtesten KI-Anwendungen im Mittelstand ist die interne Wissensdatenbank: Die KI beantwortet Fragen auf Basis Ihrer eigenen Dokumente, Handbücher und Protokolle. Technisch steckt dahinter meist ein Verfahren namens RAG, kurz für Retrieval Augmented Generation. Das Versprechen klingt beruhigend: Ihre Dokumente bleiben in Ihrer Datenbank, das Modell wird nicht mit ihnen trainiert.
Das stimmt, aber es ist nur die halbe Wahrheit. Denn damit das funktioniert, passieren zwei Dinge, über die selten gesprochen wird.
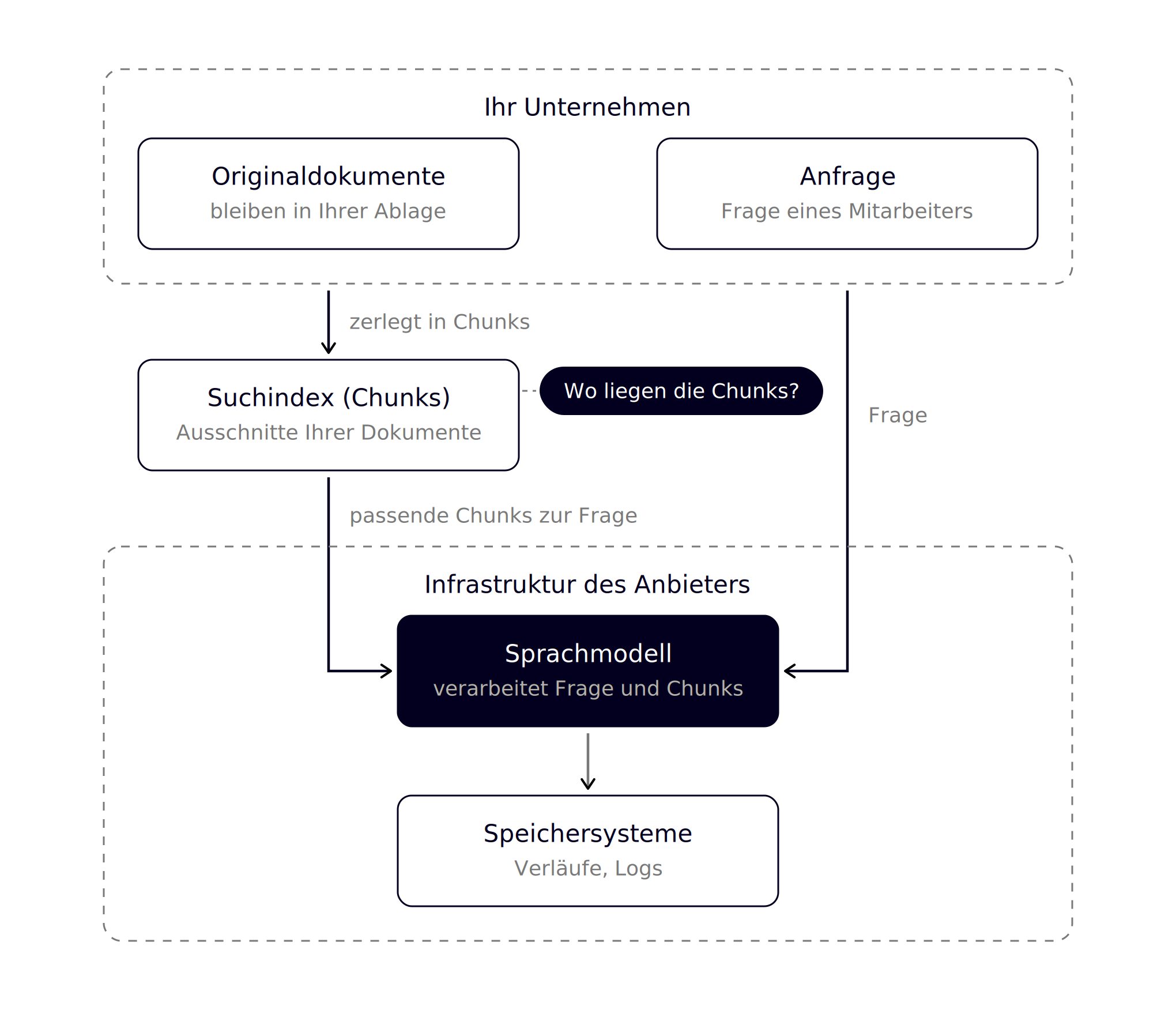
Erstens werden Ihre Dokumente für die Suche vorbereitet: Sie werden in kleine Abschnitte zerlegt, sogenannte Chunks, und in einer durchsuchbaren Form abgelegt. Diese Chunks sind nichts anderes als Ausschnitte Ihrer Originaldokumente, und sie liegen nicht zwangsläufig dort, wo die Originale liegen. Je nach Lösung landen sie in einem Cloud-Dienst des Anbieters, in einer separaten Suchdatenbank oder im eigenen Haus. Genau das muss geklärt werden: Wo werden die Chunks gespeichert, unter welchem Vertrag und mit welchen Zugriffsrechten? Eine Wissensdatenbank, deren Originale sicher im Keller liegen, deren Ausschnitte aber ungeklärt in einer fremden Cloud, hat das Vertraulichkeitsproblem nur verschoben.
Zweitens reisen bei jeder Frage die passenden Ausschnitte zum Sprachmodell. Wenn ein Mitarbeiter die Wissensdatenbank nach den Konditionen eines Kunden fragt, werden die relevanten Chunks an das Modell geschickt, damit es antworten kann. Für diesen Weg gelten dieselben Regeln wie für jede andere Eingabe: Wird gespeichert? Wird trainiert? Wo läuft das Modell? Die Wissensdatenbank befreit Sie also nicht von den Fragen aus diesem Artikel, sie macht sie nur eine Ebene konkreter.
Das ist kein Argument gegen RAG, im Gegenteil: Richtig aufgesetzt ist es einer der sichersten Wege, KI mit Firmenwissen arbeiten zu lassen. Aber „die Daten bleiben bei uns“ ist eine Aussage, die man sich im Detail zeigen lassen sollte, nicht eine, die man glauben muss.
Fünf Fragen, die jeder Anbieter beantworten muss
Wer ein KI-Werkzeug für den Geschäftseinsatz prüft, braucht keine fünfzig Kriterien. Fünf Fragen trennen die Spreu vom Weizen:
Werden unsere Eingaben für das Training verwendet?
Die Antwort muss ein vertraglich zugesichertes Nein sein, nicht eine Einstellung, die jeder Nutzer selbst finden muss.Wie lange werden Eingaben gespeichert, und können wir das steuern? Seriöse Geschäftsversionen lassen Sie Aufbewahrungsfristen festlegen oder Verläufe löschen.
Gibt es einen Auftragsverarbeitungsvertrag nach DSGVO? Ohne den ist der Einsatz mit personenbezogenen Daten nicht zulässig, Punkt.
Wo werden die Daten verarbeitet? USA mit Rechtsgrundlage, EU-Rechenzentrum oder gar lokal im eigenen Haus: Alle drei können richtig sein, aber Sie müssen es wissen.
Wer beim Anbieter kann unsere Eingaben einsehen, und wann? Auch bei ausgeschlossenem Training gibt es oft Ausnahmen, etwa zur Missbrauchskontrolle. Die sollten benannt und eng begrenzt sein.
Ein Anbieter, der auf diese Fragen ausweichend antwortet, hat sich damit bereits disqualifiziert. Ein Anbieter, der sie klar beantwortet, verdient zumindest die nächste Runde. Und wenn es um eine Wissensdatenbank geht, kommt die sechste Frage hinzu: Wo genau werden die Chunks gespeichert?
Was das für Ihren nächsten Schritt bedeutet
Vertraulichkeit ist beim KI-Einsatz kein Grund zum Abwarten, sondern eine Gestaltungsaufgabe. Drei Dinge reichen für den Anfang.
Geben Sie Ihrem Team eine offizielle, geschäftstaugliche Lösung. Das wirksamste Mittel gegen Schatten-KI ist nicht das Verbot, sondern ein erlaubter Weg, der funktioniert.
Sortieren Sie Ihre Daten nach dem Ampelprinzip, bevor Sie über Werkzeuge entscheiden. Wer weiß, welche Daten das Haus nicht verlassen dürfen, kann gezielt auswählen, statt pauschal zu hoffen oder zu verbieten.
Und stellen Sie jedem Anbieter die fünf Fragen, schriftlich. Die Antworten gehören in den Vertrag, nicht ins Verkaufsgespräch.